CubeCL Rust GPU计算教程 新手也能学会的高性能开发,只需要rust和cubel基础知识即可实现!
CubeCL是一个现代化的Rust GPU计算框架,它让编写高性能、可移植的GPU内核变得简单。通过CubeCL,你可以:
使用熟悉的Rust语法编写GPU代码
无需深入掌握复杂的GPU编程知识
轻松切换不同后端(WGPU/CUDA等)
自动优化SIMD并行计算
为什么选择CubeCL?
简单易用 :用Rust写GPU代码,学习曲线平缓高性能 :自动向量化优化,充分利用GPU算力 可移植 :同一份代码可运行在WGPU/CUDA等不同后端类型安全 :Rust的类型系统保证代码安全性
提示:即使没有GPU编程经验,通过本教程你也能快速上手CubeCL!
环境配置 配置CubeCL非常简单,只需在Cargo.toml中添加依赖:
1 2 [dependencies] cubecl = { version = "0.4.0" , features = ["wgpu" ,"default" ,"std" ] }
功能说明:
wgpu:使用WGPU后端(跨平台)std:启用标准库支持
小贴士:开发时建议同时启用wgpu和cuda特性,这样可以灵活切换后端测试
1 2 [dependencies] cubecl = { version = "0.4.0" ,features = ["wgpu" ,"cuda" ,"default" ,"std" ] }
第一个GPU程序 让我们从一个简单的GPU计算程序开始。虽然初看可能有些复杂,但我们会逐步解析每个部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 use cubecl::prelude::*;#[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>) { if ABSOLUTE_POS_X < input.len () { output[ABSOLUTE_POS_X] = gelu_scalar (input[ABSOLUTE_POS_X]); } } #[cube] fn gelu_scalar <F: Float>(x: Line<F>) -> Line<F> { add (x, x/2.0 ) } #[cube] fn add <F:Float>(a:Line<F>, b:Line<F>) -> Line<F> { a + b } pub fn lanch_test <R: Runtime>(device: &R::Device) { let client = R::client (device); let input = &[5f32 ;8 ]; let vectorization = 4 ; let output_handle = client.empty (input.len () * core::mem::size_of::<f32 >()); let input_handle = client.create (f32 ::as_bytes (input)); unsafe { gelu_array::launch::<f32 , R>( &client, CubeCount::Static (1 , 1 , 1 ), CubeDim::new ( 2 , 1 , 1 ), ArrayArg::from_raw_parts::<f32 >(&input_handle, input.len (), vectorization as u8 ), ArrayArg::from_raw_parts::<f32 >(&output_handle, input.len (), vectorization as u8 ), ) }; let bytes = client.read_one (output_handle.binding ()); let output = f32 ::from_bytes (&bytes); println! ("GPU计算结果(Runtime: {:?}) => {:?}" , R::name (), output); } fn main () { type Runtime = cubecl::wgpu::WgpuRuntime; let device = Default ::default (); launch_test::<Runtime>(&device); }
虽然这段代码初看有些复杂,但CubeCL的设计实际上隐藏了许多GPU编程的复杂性。让我们分解理解每个部分:
核心概念解析 1. Runtime(运行时) Runtime是CubeCL的核心概念之一,它决定了你的代码将在哪种GPU后端上运行:
1 type Runtime = cubecl::wgpu::WgpuRuntime;
在cubecl中,runtime代表了我们的gpu运算将基于什么去运行,这里我选择的是wgpu,同理,我们也可以将他换成为cuda。
2. Device(设备) Device代表实际的运算硬件。现代计算机可能有:
独立显卡(Discrete GPU)
集成显卡(Integrated GPU)
CPU(作为后备)
虚拟GPU(如云环境)
CubeCL支持灵活选择设备:
1 let device = WgpuDevice::Cpu;
1 let device = WgpuDevice::DiscreteGpu (0 );
1 let device = WgpuDevice::IntegratedGpu (0 );
1 let device = WgpuDevice::VirtualGpu (0 );
3. Client(客户端) Client是连接CPU和GPU的桥梁,主要功能包括:
1 let client = R::client (device);
client 是 GPU 运行时(如 CUDA 或 OpenCL)的高层抽象 ,封装了以下功能:
内存管理 :分配/释放 GPU 显存(如 client.create() 和 client.empty())。数据传输 :在 CPU 内存和 GPU 显存之间拷贝数据(如 client.read_one())。内核执行 :提交 GPU 内核(Kernel)启动命令到设备队列。
其中
1 2 3 4 5 R::client (device) 创建与指定GPU设备(device)绑定的运行时客户端。 client.create (data) 将CPU数据(data)拷贝到GPU显存,返回显存句柄(input_handle)。 client.empty (size) 在GPU显存中分配未初始化的空间(大小为size字节),返回句柄。 client.read_one (handle) 将GPU显存中的数据(通过handle标识)读回CPU内存。 gelu_array::launch (client, ...) 通过client提交内核执行任务到GPU队列。
可以说**client 是GPU编程的入口**,它负责连接设备、管理数据、执行任务。
GPU内核编程 与传统GPU编程不同,CubeCL允许直接用Rust编写运算逻辑。关键点是#[cube]宏:
1 2 3 4 #[cube] fn add <F:Float>(a:Line<F>, b:Line<F>) -> Line<F> { a + b }
核心特点:
使用Rust语法,无需学习新语言
Line<T>类型表示可向量化数据自动生成优化的GPU代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>) { if ABSOLUTE_POS< input.len () { output[ABSOLUTE_POS] = gelu_scalar (input[ABSOLUTE_POS_X]); } } #[cube] fn gelu_scalar <F: Float>(x: Line<F>) -> Line<F> { add (x,x/2.0 ) } #[cube] fn add <F:Float>(a:Line<F>, b:Line<F>) -> Line<F> { a+b }
#[cube]宏详解#[cube]宏标记的函数将在GPU上执行,支持多种变体:
宏变体
用途
#[cube]基本GPU函数
#[cube(launch)]生成可启动的内核入口函数
#[cube(debug)]调试模式,打印生成代码
在这个“入口”函数中,我们是如下定义的
1 2 #[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>)
官方是这么描述line的,我们的数据就从这里进入。
正常情况下,使用launch去创建一个“入口”,之后我们就可以调用 函数名::launch了,如下
1 2 3 4 5 6 7 gelu_array::launch::<f32 , R>( &client, CubeCount::Static (1 , 1 , 1 ), CubeDim::new (2u32 , 1u32 , 1u32 ), ArrayArg::from_raw_parts::<f32 >(&input_handle, input.len (), vectorization as u8 ), ArrayArg::from_raw_parts::<f32 >(&output_handle, input.len (), vectorization as u8 ), );
我们发现这里比我们设定的参数多了好多东西,最开始所传入的就是我们所生成的client,也就是调用gpu的那个接口,接下来的东西比较多,我们需要慢慢解释。
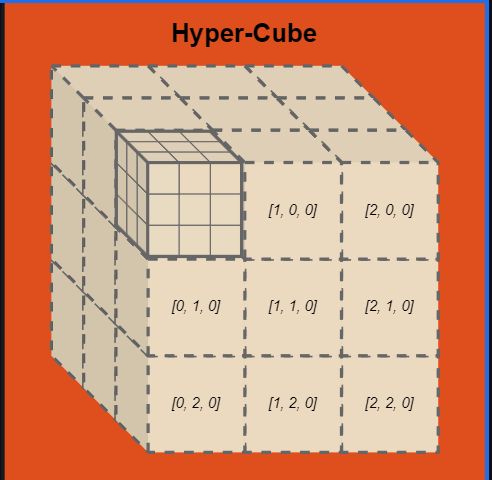
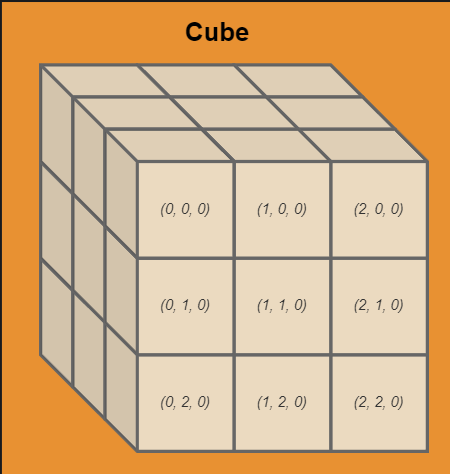
GPU并行模型 CubeCL使用独特的”多维立方体”模型管理GPU并行:
Hyper-Cube :顶层并行单元,由CubeCount::Static定义数量Cube :中层并行单元,由CubeDim::new定义尺寸Unit :基础执行单元,包含向量化数据
这种抽象让并行计算更直观,Hyper-Cube又由Cube构成:
Cube由unit构成
最小单元就是unit每个unit中可以存放的数据量就是vectorization,当然这个也可以理解为一个uint的线程数。
启动配置示例 1 2 3 4 5 6 7 gelu_array::launch::<f32 , R>( &client, CubeCount::Static (1 , 1 , 1 ), CubeDim::new (2 , 1 , 1 ), input_arg, output_arg, );
这个配置表示:
总计算量:8个元素(4向量宽度 × 2 × 1 × 1)
完美匹配数组长度时性能最佳
性能计算技巧 合理配置可以最大化GPU利用率:
总量计算 :
1 总元素 = 向量宽度 × (Cube.x × Cube.y × Cube.z) × (HyperCube.x × HyperCube.y × HyperCube.z)
X轴计算 :
1 X轴元素 = 向量宽度 × Cube.x × HyperCube.x
最佳实践 :
使总元素数略大于实际数据量
优先扩展X轴维度
保持向量宽度为4或8的倍数
至于为什么要计算这个,我们还要先回到运算逻辑代码处,我们先说明这段代码的作用
1 2 3 4 5 6 #[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>) { if ABSOLUTE_POS< input.len () { output[ABSOLUTE_POS] = gelu_scalar (input[ABSOLUTE_POS]); } }
这里虽然并没有出现for循环,但我们可以理解再这个函数内部是不断循环的,其中ABSOLUTE_POS就是不断遍历的下标,去执行我们定义的函数。同理下面这个是只遍历x轴上的unit,将每个x轴上的unit进行gelu_scalar函数处理,进行单列运算
1 2 3 4 5 6 #[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>) { if ABSOLUTE_POS_X < input.len () { output[ABSOLUTE_POS_X] = gelu_scalar (input[ABSOLUTE_POS_X]); } }
循环展开 循环展开(Loop Unrolling) 是一种通过减少循环控制开销(如分支判断、计数器更新)来提升性能的优化技术。它通过将循环体内的代码重复多次,减少循环迭代次数,从而提高指令级并行性(ILP)和内存访问效率。以下是 CUDA 循环展开的详细解释和实现方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #[cube(launch_unchecked)] fn sum_basic <F: Float>(input: &Array<F>, output: &mut Array<F>, #[comptime] end: Option <u32 >) { let unroll = end.is_some (); let end = end.unwrap_or_else (|| input.len ()); let mut sum = F::new (0.0 ); #[unroll(unroll)] for i in 0 ..end { sum += input[i]; } output[UNIT_POS] = sum; }
高级话题:矩阵运算 处理矩阵需要同时考虑X和Y维度:
1 2 3 4 5 6 7 8 #[cube(launch)] fn gelu_array <F: Float>(input: &Array<Line<F>>, output: &mut Array<Line<F>>) { if ABSOLUTE_POS_X < input.len () { if ABSOLUTE_POS_Y < output.len () { output[ABSOLUTE_POS_X+ABSOLUTE_POS_Y *【x每行unit的个数】] = gelu_scalar (input[ABSOLUTE_POS_X+ABSOLUTE_POS_Y *【x每行unit的个数】]); } } }
关键点:
使用ABSOLUTE_POS_X和ABSOLUTE_POS_Y访问二维索引
手动计算线性索引
确保边界检查
当然,仅仅是处理一个参数在世界情况中还是并不常见,那么多个参数的情况也很简单,只需要在队伍的lauch中添加参数即可
1 2 3 4 5 6 7 8 #[cube(launch)] fn gelu_array <F: Float>(input1: &Array<Line<F>>,input2:&Array<Line<F>>,output: &mut Array<Line<F>>) { if ABSOLUTE_POS_X < input1.len () { if ABSOLUTE_POS_Y < output.len () { output[ABSOLUTE_POS_X+ABSOLUTE_POS_Y*2 ] = add (input1[ABSOLUTE_POS_X+ABSOLUTE_POS_Y*2 ],input2[ABSOLUTE_POS_X+ABSOLUTE_POS_Y*2 ]); } } }
1 2 3 4 5 6 7 8 gelu_array::launch::<f32 , R>( &client, CubeCount::Static (2 , 1 , 1 ), CubeDim::new (2u32 , 2u32 , 1u32 ), ArrayArg::from_raw_parts::<f32 >(&input_handle, input.len (), vectorization as u8 ), ArrayArg::from_raw_parts::<f32 >(&input_handle, input.len (), vectorization as u8 ), ArrayArg::from_raw_parts::<f32 >(&output_handle, input.len (), vectorization as u8 ), )
实现一个加速反色 cpu处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use image::{ImageBuffer, Rgb, RgbImage};fn main () { let img = image::open ("./../image.jpg" ).unwrap (); let rgb_img = img.to_rgb8 (); let mut buffer : RgbImage = ImageBuffer::new (rgb_img.width (), rgb_img.height ()); for (x, y, pixel) in rgb_img.enumerate_pixels () { let inverted = Rgb ([ 255 - pixel[0 ], 255 - pixel[1 ], 255 - pixel[2 ], ]); buffer.put_pixel (x, y, inverted); } buffer.save ("./../output.jpg" ).unwrap (); }
gpu处理,这里可以看到cubecl使用的并不只有泛型,还可以使用u32等类型去运算,但必需保证运算的类型是可以被支持的,否则会出现以下错误
1 U8 is not a valid WgpuElement
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 extern crate core;use core::u32 ;use cubecl::prelude::Float;use std::ops::Sub;use cubecl::prelude::*;use cubecl::wgpu::WgpuDevice;use image::{ImageBuffer, Rgb};#[cube(launch)] fn gelu_array (input1: &Array<Line<u32 >>,output: &mut Array<Line<u32 >>) { if ABSOLUTE_POS < input1.len () { output[ABSOLUTE_POS] = gelu_scalar (input1[ABSOLUTE_POS]) } } #[cube] fn gelu_scalar (x: Line<u32 >) -> Line<u32 > { minus (x) } #[cube] fn minus (a:Line<u32 >) -> Line<u32 > { Line::new (u32 ::max_value ())-a } pub fn launch <R: Runtime>(device: &R::Device,list:&[u8 ],w:u32 ,h:u32 ) { let client = R::client (device); let vectorization = 4 ; let output_handle = client.empty (list.len () * core::mem::size_of::<u8 >()); let input_handle = client.create (list); unsafe { gelu_array::launch::<R>( &client, CubeCount::Static (8000 , 1 , 1 ), CubeDim::new (100u32 , 10u32 , 1u32 ), ArrayArg::from_raw_parts::<u32 >(&input_handle, list.len (), vectorization as u8 ), ArrayArg::from_raw_parts::<u32 >(&output_handle, list.len (), vectorization as u8 ), ) }; let bytes = client.read_one (output_handle.binding ()); let bytes2 = client.read_one (input_handle.binding ()); let b : ImageBuffer<Rgb<u8 >, Vec <u8 >> = ImageBuffer::from_raw (w,h,bytes).unwrap (); b.save ("./../output.png" ).unwrap (); } fn main () { type Runtime = cubecl::wgpu::WgpuRuntime; let device = WgpuDevice::default (); let img = image::open ("./../image.jpg" ).unwrap (); let rgb_img = img.to_rgb8 (); let (w,h) = rgb_img.dimensions (); let buf = rgb_img.into_raw (); launch::<Runtime>(&device,&buf,w,h); }